
 [罗戈导读]作者简介:蔡智武 达达-京东到家大数据产品研发负责人,毕业于上海交通大学软件学院,有多年数据仓库和数据平台系统建设及团队管理经验,2017年加入达达-京东到家,负责达达-京东到家大数据平台整体规划及产品研发工作。
[罗戈导读]作者简介:蔡智武 达达-京东到家大数据产品研发负责人,毕业于上海交通大学软件学院,有多年数据仓库和数据平台系统建设及团队管理经验,2017年加入达达-京东到家,负责达达-京东到家大数据平台整体规划及产品研发工作。


达达-京东到家大数据平台是根据公司业务持续快速成长,而规划建设的一个可持续发展的平台。在建设过程中我们借鉴了很多公司实施大数据平台的经验,并因地制宜构建了我们自己的实施策略,确保在大方向上不会走偏,并且每一年都会有重大变化和质的成长。
建设回顾

图1 大数据平台建设历程
2016年——DRP平台建设
这个阶段数据仓库还是Mysql,所有工作几乎都是围绕着短、平、快实现重要核心报表而开展,DRP的成功实施大大减少了分析师的工作量,给公司数据驱动换上了新的引擎。
2017年——工具专业化建设
这个阶段数据仓库已经换成Hive,因为mysql实在跑不动了,但是围绕数据的一些工具都是空白的,分析师需要靠自己强大的记忆力来记住重要的元数据信息,业务部门也只能通过分析师获取数据。在这一年,统一权限管理、元数据平台、自助报表平台、自助查询平台、数据交换平台等工具应运而生,让数据开放由设想变成实际可行。
2018年——应用体系化建设
由于历史原因,这个时候整个平台技术和应用体系其实还是挺参差不齐的,随之而来的是系统稳定性比较差,DW值班人员经常需要起夜处理问题。这一年我们花大力气重构了调度开发平台、需求管理平台,研发了数据质量监控系统,优化了权限体系、报表体系、查询体系和数据交换体系,自研了E-SQL来解决HUE糟糕的使用体验。同时,在数据服务和数据应用的建设上有了实际性的进展,各种数据开始通过数据服务中台更加直接的影响业务,苍穹系统也探索完成首个业务模块。
2019年——资产生态化建设
2019年的主要方向是让数据回归资产本质,让平台拥有生态体系,让应用实现产品驱动。我们会在数据仓库建设上提炼行业数据资产;在计算引擎、存储引擎、安全引擎及同步引擎上实现平台生态化;在苍穹系统建设上用更加产品化的思维帮助业务方发现问题并提供解决方案,提升大家的工作效率。
下面我将简单介绍一下当前达达-京东到家大数据平台的总体框架及主要组成部分的情况,并结合这些模块的建设过程来阐述一下我们的实施策略。
总体框架

图2 大数据平台总体框架
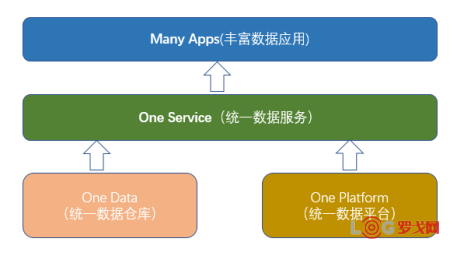
达达-京东到家大数据平台作为同时支持公司达达物流和京东到家两大事业群发展的基础平台,它由四部分组成:
统一的数据仓库(One Data)、
统一的数据平台(One Platform)、
统一的数据服务(One Service)、
丰富的数据应用(Many Apps)
如图2所示,数据仓库和数据平台是基础构件,数据服务是将数据开放出去的中轴,而数据应用是数据价值的最终体现者,整个大数据平台建设致力于成为物流和零售行业数据驱动的标杆。

图3 数据仓库主题
统一的数据仓库涉及物流和到家共计22个主题域,5000+的离线任务,120+的实时任务,数PB数据总量。在数据仓库领域我们主要考虑的因素是覆盖面、准确性及稳定性。
1、覆盖面
数据覆盖面是决定数据仓库能否支持所有业务的基础。想要完全覆盖一个快速迭代和发展的业务,跟着业务系统走是行不通的,我们必须站在数据仓库的视角来审视覆盖的内容行业本质和用户行为。如果把行业本质和用户行为的内容都覆盖了,那数据仓库的覆盖面就是完整的,需要解决的只是内容的丰富度而已。
从图3看出,我们在达达物流及京东到家的数据主题域规划上是分开的,但基本上大同小异。拿物流举例:从行业本质来说,物流是将一个客户的物品配送到另外一个客户,会产生账户交易和财务结算;从用户行为来说,为了做好物流这个事,我们需要有公司的组织保障、必要的市场营销及良好的客户售后服务,这些用户行为将共同沉淀下来客户端设备信息、位置信息及流量日志信息等。对到家来说,商品销售和社区管理是零售不可或缺的重要组成部分,而这个不是物流的必要组成部分。
2、准确性
数据准确性是数据仓库产生价值的根本。我们通过统一数据源、统一数据建模、集中ETL处理来规避了源头的不一致、模型的二义性及处理逻辑的偏差,同时通过数据质量系统对核心指标做了监控预警,确保提供给出去的数据是准确无误的。
3、稳定性
稳定性是衡量数据仓库成熟度最重要的因素。只有覆盖度和准确性,数据却不能稳定交付是不行的,我们在稳定性提升的路上走得并不是太顺利,很长一段时间这都是困扰我们的存在。为了保证稳定性,我们采用了事前预防、事中处理及事后复盘等多种策略,目前稳定性已经明显好转。几个重要的事情说明一下:
① 数据源探测:离线抽数和推数任务成百上千,任何一个数据源的变动都会导致任务报错。虽然与DBA保持了良好的沟通,但是通过人工预判总是会疏漏一些结构变化,每天定期做数据源探测则让问题提前暴露,让夜间抽数、推数报错的概率大大降低。
② ETL优化解耦:集群的资源永远是不够用的,ETL性能优化及链路解耦是日常有空就得做的事情。好处很明显,正常执行可以节省资源,异常重跑还可以节省时间。
③ 调度集群化:5000多个离线任务依赖调度系统运行,调度系统的高可用是非常核心的事情,任何一个调度环节出现单点故障,整个任务就会堵住,而大数据调度系统是个很复杂的系统,里面集成了很多任务类型的引擎,异常情况重新部署无论从资源协调还是部署时间上讲都是不可行的。在调度未集群化之前,我们碰到过好几次硬件故障导致只能等硬件抢修的情况,调度集群化之后我们在好几次硬件宕机的情况下都安然无恙挺过。
④ 多重预警:期待不出问题是不可能的,当问题发生时及时的人工干预就是最后的兜底。我们设置了值班人员-任务开发者-ETL负责人-部门负责人四道防线来确保不会漏接异常预警;同时我们设置了进度预警机制,确认任务挂起不报错的情况下能够发现问题。
⑤ 运维专业化:Hadoop是个复杂的平台,集群上了规模之后,运维专业化非常必要。我们严格拆分了实时集群和离线集群,任何一个配置变动都需要经过研发和运维的双重审核。到目前为止,离线集群已经一年多没有重启了,相对于早期“重启是解决一切疑难杂症的最后良药”,这已经是很大的进步了。

图4 数据平台模块
统一的数据平台涵盖统一权限、开发平台、数据采集、存储引擎、计算引擎、资源管理和数据应用等组件的封装和集成,如图4所示。
① 统一权限平台:权限管理是数据安全的基础,Hadoop生态的权限管理做的非常一般,覆盖不全、实施复杂及性能瓶颈的问题都会遇到,基于这个原因我们是自研了权限管理平台,将hdfs、hive、presto、kafka、es、redis等离线和实时的数据对象做了统一管理和授权,同时与公司的ldap打通,保障用户的使用体验。
② 调度开发平台:大数据平台的调度开发平台有别于线上的纯调度系统,为了保障开发的体验及运行的可控,我们集成了离线任务、近线任务、实时任务及任务预警等很多引擎,与git集成支持版本管理,同时保障多机房、多集群、负载均衡等任务分发机制,它已经是我们所有系统中最复杂的一个系统。目前配置2个主节点,每个机房或者每个集群同时配置2个以上的执行从节点,任何一个节点出现问题,其它多活节点都可以无缝托管这个问题节点的任务。
③ 数据源及采集:目前主流的关系型数据库、Kafka、文本文件及非关系型数据库等都支持配置化抽取。同时支持对MYSQL智能增量抽取,所有目标表及分区智能创建,大幅提升了ETL开发的工作效率。
④ 数据存储:离线数据按天以上的频度更新,以Hive、HDFS和Hbase存储为主;近线数据按分钟级的频度更新,以Hive存储为主,通过Presto提供查询;实时数据根据应用的特性会存放在kafka、redis、hbase、es、druid及mysql中。
⑤ 资源管理:资源管理这块没有做太多了封装,主要基于Yarn做了部分队列的资源限制和权限限制。
⑥ 数据计算:实时计算引擎我们早期是基于Spark Streaming定制开发,目前已经基本迁移到Flink,并且基于开源的FLinkStreamSQL封装了我们自己基于SQL的流式任务;近线计算引擎我们早期是基于Spark SQL定制开发,目前已经全部迁移到封装好的基于SQL的Spark SQL引擎,并且同时支持Spark 1.6和Spark 2.2,与此同时我们所有的数据都支持以Presto引擎对用户开放;离线计算引擎以Hive为主,我们正计划通过封装好的Spark SQL来逐步代替Hive引擎。
⑦ 数据应用:目前数据应用主要包括数据产品、查询体系、算法应用、数据分析以及数据服务等这几个方向。每个方向的用户群体和使用场景都不太一样,在设计应用架构时需要特别考虑这些因素,以精简实用为主,避免周期长、大而全的建设,那样研发试错成本及应用实用化会是非常大的问题。

图5 数据中台服务
统一的数据服务整合了优质的数据仓库和数据平台资源,将数据以最短链路提供给数据应用、线上业务及开放平台,如图5所示,承担的是数据中台的职责,目标是让内外部应用更加便捷的获取到数据,加速数据的利用。统一数据服务是个逻辑上的概念,更侧重于归口建设、统一标准和集中管理,物理部署上我们是分开的。
① 中间库服务:早期数据服务很简单,就是提供中间库服务,谁要数据去中间库取。随着应用的深入和数据量的增加,中间库接口实现起来不仅费时费力,而且无法承载大数据量的交互。鉴于此,我们增加文件存储服务和API服务。
② 存储服务:通过把数据转化成文本,存放到共享的sftp、http存储及云盘等,需求方只要下载文件就可以解释入库,解决了大数据量交互的问题,但需求方还是需要开发对应的解释入库程序。
③ API服务:对于单次数据获取量不大,让数据需求方开发中间库服务或者存储服务接口,成本上比较高,而且同一接口不同需求方要重复建设,确实影响效率和浪费成本。鉴于此,通过数据部集中设计和开发api服务就应运而生,最开始我们每个api接口都需要定制开发,目前我们已经研发了基于配置化的通用服务,对redis、hbase、es、druid、mysql等存储引擎的数据,通过配置一个简单的SQL或者一些表和字段名就能很方便的开发出一个数据服务接口。

图6 数据应用模块
丰富的数据应用包括了BI自建应用、共享平台应用以及共建业务应用等三部分,如图6所示。
① BI自建应用:包含以苍穹平台为主的数据运营体系,以DRP和MiniReport为主的报表体系,以MyQuery和E-SQL为主的查询体系,以调度开发为主的数据平台体系,以及在移动端、H5端和微信端的各种定制数据产品应用。
② 共享平台应用:在BI自建应用中My-Query、MiniReport作为共享平台开放给了公司总部所有业务部门,调度开发平台开放给了BI相关部门,这三个平台支持用户在上面构建属于自己的应用或者任务;
③ 共建业务应用:包括了以平台、商户和品牌为主的CRM体系,以物流和到家算法为主的算法应用,以及围绕订单、配送、商户、商品、营销、广告等业务的线上业务应用。在这些系统的建设过程中,数据中台服务发挥了重大作用,将复杂的数据计算与整合环节全部交给数据部,业务部门只要专注于实现业务场景即可,实施效率得到了大幅度的提升。
对BI自建应用和共享平台来说,使用频次是考核这个系统是否成功的重要标准。基于研发资源状况,我们并没有追求应用的数量,而是争取把每个应用质量做到最好。到目前为止,DRP、灯塔、MiniReport、MyQuery、E-SQL等系统的查询频次都达到了每天数千人次,为业务部门获取数据提供了极为方便且多样的选择;同时,我们对DRP的官方报表做了严格筛选,到目前为止也没超过300个,但共享平台MiniReport和MyQuery上的自助报表和自助查询数据都达到了600+,它们为业务探索期间的数据获取及监控提供了简单有效的解决方案,深受公司内广大用户喜欢。
总结展望
如果用一个人的成长期来比喻,那么达达-京东到家大数据平台正好进入了青年期,在经过了懵懂的少年期之后,正在快速的向壮年期迈进,我们将会在数据赋能及技术纵深领域做出更多积极的探索。


首发 | 富勒科技完成3亿元融资,经纬领投,高成和高瓴跟投
8751 阅读
苹果社招运营与供应链类岗位
4388 阅读
华住集团2025届秋季校园招聘供应链管理等岗位
4215 阅读白象食品2025全球校园招聘供应链类等岗位,截至25年6月1日
3889 阅读顺丰社招运作主管;KA客户经理;SME客户经理;供应链财务岗;网点主管等
3754 阅读淘天物流部社招履约产品、产品经理、商业数据分析
3336 阅读中国物流集团社招仓库管理员-泰州;财务出纳专员-常州;人力资源管理-北京市-丰台区
3275 阅读宁德时代社招物流工程师-YBSJ;高级物流工程师-进出口;海外物流规划工程师;物流规划工程师;机械工程师(物流)
3203 阅读招贤纳新丨美通招聘这些岗位人才
2954 阅读贝泰妮集团2025届校园招聘供应链岗位等,截止11.30
2953 阅读







粤公网安备 44030402005698号




















